Passport checks at airports and border gates present a special challenge: How do you tell if the person standing in front of you is the same person whose picture is in the passport? Border and customs officers solve this problem using the complex mechanisms ingrained in the human visual system through billions of years of evolution.
It’s not a perfect process, but it works well most of the time.

In the realm of artificial intelligence, this is called the “one-shot learning” challenge. In a more abstract way, can you develop a computer vision system that can look at two images it has never seen before and say whether they represent the same object?
[Read: New polymer coating could help brains merge with machines — cyborgs incoming?]
Data is one of the key challenges in deep learning, the branch of artificial intelligence that has had the most success in computer vision. Deep learning algorithms are notorious for requiring large amount of training examples to perform simple tasks such as detecting objects in images.
But interestingly, if configured properly, deep neural networks, the key component of deep learning systems, can perform one-shot learning on simple tasks. In recent years, one-shot learning AI has found successful applications including facial recognition and passport checks.
[embedded content]
Classic convolutional neural networks
One of the most important architectures used in deep learning is the convolutional neural network (CNN), a special type of neural net that is especially good at working with visual data.
The classic use of CNNs is to set up multiple convolution layers (with some other important components in-between and after), specify an output goal, and train the neural network on many labeled examples.
For instance, an image classifier convnet takes an image as input, processes its pixels through its many layers, and outputs a list of values that represent the probability that the image belongs to one of the classes it detects.

The neural network can be trained on one of several public datasets such as ImageNet, which contains millions of images labeled with more than a thousand classes. As the convnet iterates through the training images, it tunes its millions of parameters to be able to determine the class of each image.
One of the interesting features of convnets is their ability to extract visual features from images at different levels. A trained convolutional neural network develops a hierarchical structure of features, starting with smaller features in first layers and larger and higher-level features in the deeper layers.
When an image goes through the CNN, it encodes the image’s features into a set of numerical values and then uses these values to determine which class the image belongs to. With enough training examples, a convnet can generalize the feature encoding process well enough to be able to associate new images to their proper class.
Most modern computer vision applications use convolutional neural networks.

Instead of ImageNet (or other public datasets), developers can use their own curated training data. But due to the costs of gathering and labeling the images, they usually use a public dataset to train their model, and then finetune it on a smaller dataset that contains the images specific to their problem.
Repurposing CNNs for one-shot learning
One of the key problems in many computer vision problems is that you don’t have many labeled images to train your neural network. For instance, a classic facial recognition algorithm must be trained on many images of the same person to be able to recognize her.
Imagine what this would mean for a facial recognition system used at an international airport. You would need several images of every single person who would possibly pass through that airport, which could amount to billions of images. Aside from being virtually impossible to gather such a dataset, the notion of having a centralized store of people’s faces would be a privacy nightmare.
This is where one-shot learning comes into play. Instead of treating the task as a classification problem, one-shot learning turns it into a difference-evaluation problem.
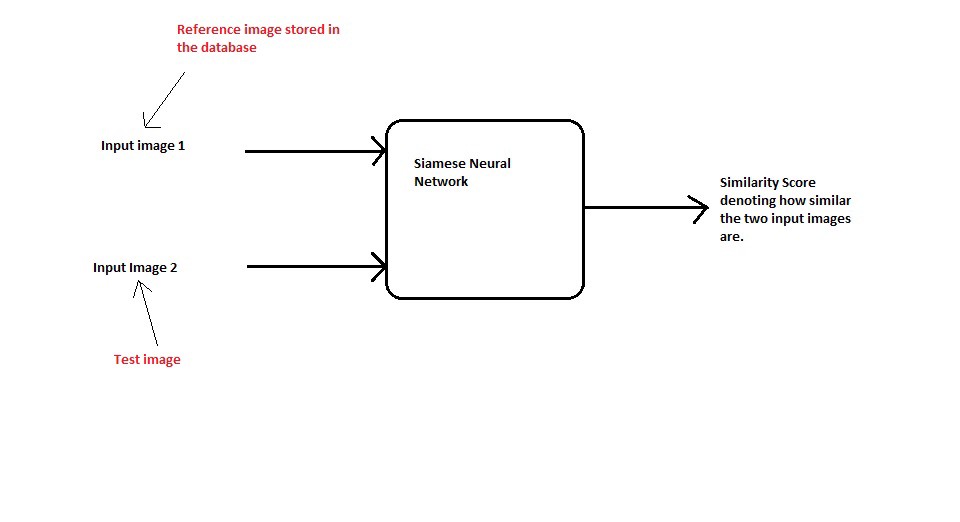
When a deep learning model is adjusted for one-shot learning, it takes two images (e.g., the passport image and the image of the person looking at the camera) and returns a value that shows the similarity between the two images. If the images contain the same object (or the same face), the neural network returns a value that is smaller than a specific threshold (say, zero) and if they’re not the same object, it will be higher than the threshold.

Siamese neural networks and the triplet loss function
The key to one-shot learning is an architecture called the “Siamese neural network.” In essence, the Siamese neural network is not much different from other convolutional neural nets. It takes images as input and encodes their features into a set of numbers. The difference comes in the output processing.
During the training phase, classic CNNs tune their parameters so that they can associate each image to its proper class. The Siamese neural network, on the other hand, trains to be able to measure the distance between the features in two input images.

To achieve this goal, we use a function called “triplet loss.” Basically, the triplet loss trains the neural network by giving it three images: an anchor image, a positive image, and a negative image. The neural network must adjust its parameters so that the feature encoding values for the anchor and positive image are very close while that of the negative image is very different.
Hopefully, with enough training examples, the neural network will develop a configuration that can compare high-level features between APN trios. For instance, in the case of the facial recognition example, a trained Siamese neural network should be able to compare two images in terms of facial features such as distance between eyes, nose, and mouth.
[embedded content]
Training the Siamese network still requires a fairly large set of APN trios. But creating the training data is much easier than the classic datasets that need each image to be labeled. Say you have a dataset of 20 face images from two people, which means you have 10 images per person. You can generate 1,800 APN trios from this dataset. (You use the 10 pictures of each person to create 10×9 AP pairs and combine it with the remaining 10 images to create a total of 10x9x10x2 = 1800 APN trios)
With 30 images, you can create 5,400 trios, and with 100 images, you can create 81,000 APNs. Ideally, your dataset should have a diversity of face images to better generalize across different features. Another good idea is to use a previously trained convolutional neural network and finetune it for one-shot learning. This process is called transfer learning and is an efficient way to cut down the costs and time of training a new network.
Once the Siamese network is trained, if you provide it two new face images (e.g., passport and camera input), it should be able to tell you if they are similar enough to be the same person or not.
So you no longer need to train your facial recognition deep learning model on all the faces in the world.
[embedded content]
The limits of one-shot learning
Although very attractive, one-shot learning does have some limitations. Each Siamese neural network is just useful for the one task it has been trained on. A neural network tuned for one-shot learning for facial recognition can’t be used for some other task, such as telling whether two pictures contain the same dog or the same car.
The neural networks are also sensitive to other variations. For instance, the accuracy can degrade considerably if the person in one of the images is wearing a hat, scarf, or glasses, and the person in the other image is not.
[embedded content]
One-shot learning is an exciting and active area of research. There are other variations of the method, including zero-shot and few-shot learning.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech and what we need to look out for. You can read the original article here.
Published August 19, 2020 — 16:00 UTC