
Did you know we have an online conference about digital marketing coming up? Re:Brand will share strategies on how brands can still succeed in these unprecedented times.
Let’s say you are working for a startup that sells robots across all industries. You take in orders from a variety of clients, and an operations team evaluates the orders and works with third-party providers to get your clients just the right robot.
Building the MVP was stressful but also a lot of fun. Your investors are excited and shower you with money. The next phase starts. You need more visibility on profitability and you want to acquire bigger clients that need more sophisticated invoicing. At the same time, you have a pretty sophisticated product roadmap to enable sales of higher-margin robots. Resources are scarce, but you still need to make sure to keep the company running.
As often preached for smaller companies, focusing on the things you are good at is a great rule of thumb. But what about all the areas that keep your company’s everyday operations running? You certainly don’t want to build a Customer Relationship Management (CRM) system or an accounting system. After all, there are lots of products out there that solve all the issues. But how will these systems work together with your existing order system?
This is where third-party integration comes in handy. So, let’s dive in and see if we can avoid some common pitfalls.
CRM integration
Whether you are doing low-touch sales (content marketing, social media ads, or newsletters) or high-touch sales (cold calling, attending conferences, or following up with existing clients via phone), a CRM system can give you a lot of visibility about how you are doing with existing clients and how successful you are with convincing new clients.
Oftentimes, the selection of a CRM system is mostly left to the sales and marketing department. In general, there is nothing wrong with that. After all, these people know best how to increase revenue and need the best support available. But even the best software is worth nothing if it doesn’t properly work together with your robot ordering system.
Include your tech department in the decision
Whether it’s the CTO or a dedicated engineer, keep them in the loop from the beginning. They are very likely to give you more insight on how the two systems will work together in the future.
And a word for the engineers: Keep an open mind toward third-party solutions. It’s easy to dismiss those because their API is not the best or their UI is ugly. However, it can be very rewarding to find elegant solutions around existing systems.
Nevertheless, there are a couple of topics that can be beneficial to talk about before making a decision. General topics like “Do we need this at all?” need to be addressed. But it is also a good idea to already have an idea of what the scope is. Is there a need for a two-way sync, or will the third-party system just follow the order system? Once the scope is out of the way, there also needs to be a technical discussion about implementation details such as webhooks or evaluation of the API limits.
Do you need a custom integration?
When it comes to integration, it’s not surprising that there are already existing platforms out there that promise to solve some of the problems you are likely to encounter. Currently, Zapier and IFTTT are the most promising ones.
Depending on the problem you are trying to solve, your robot order system might not even be involved in the integration. Say you are managing your newsletter subscribers with a CRM system such as Salesforce or HubSpot and just want a more convenient way to reach out to them via an email service provider such as Mailchimp, Zapier has tons of existing integrations to help you with that. From this point, choosing a provider that has a Zapier connector is a good way forward.
And even if it comes to integrating custom data (ordered robots and their price), Zapier Webhooks can act as a middleman for your integration.
On the other hand, if you are already sending data to a third party, why not send it directly to the CRM system? The more data you want to sync, the more useful a direct integration will be.
Which brings me to my next point.
Do you need two-way sync?
Usually, an integration starts out with a simple requirement such as Can we get all our clients into our CRM system?, typically combined with the values of individual robot orders, making it easier to utilize client segmentation tools.
However, sooner or later, it might be the case that people will want to make use of contact management tools that a CRM suite typically offers. These include features like deduplication, amending contact details with social media data, normalizing shipping addresses, or just simply deleting old contacts.
Changing contacts in a CRM system will most likely mean you will need to change contact details in another system, i.e., changes need to go both ways.
The implementation effort for this is way beyond a simple one-way sync, so this is an excellent point to think about how you want to use a new system strategically.
How will you be notified of changes from the CRM?
If you decide to have a two-way sync, there is a follow-up question: How do you know that something changed on the CRM side?
Most system providers have tools for this, but the best one for immediate changes is webhooks—essentially, an HTTP notification system that can be configured to let you know about relevant changes (for some systems, even on a field-by-field basis).

If the system doesn’t offer webhooks, at least check if you can get a list of all entities that have recently been updated. This way, you don’t have to go through all contacts and deals only to update your own data. But please keep in mind that you will need to poll the system on a regular interval.
In this case, your order system would still change and create data via an API call on the CRM system. But all changes from the CRM system would be polled in a defined interval.

What is worth noting is that the updates will be restricted to this interval and can lead to temporary data inconsistency. For example, when you only sync once a day from your CRM system to your order system, the data you are looking at in your order system can be up to 24 hours old.
Depending on what features the system offers, the integration task can vary in complexity and implementation time. Make sure to check what the system offers ahead of time and double check the plan you intend to buy. For example, some CRM systems offer webhooks in the higher-paid tiers.
An example here is HubSpot’s CRM, which offers webhooks in general but the webhook feature is only available in their Enterprise package. The accounting tools Zoho Books will offer five automated workflows (which include webhooks) in their lowest tier.
Is your data in good shape?
When it comes to creating data sets in an external system, it’s good to know what the data looks like in your own system. Luckily, there are not too many different ways of presenting contacts and deals, but one field that always causes trouble is the email field.
Different systems have different ideas of what a valid email address is, and here’s a spoiler alert—your clients might have provided you with invalid email addresses of all kinds. A lot of CRM systems will reject the creation of a contact with an invalid email address (and of course, the CRM provider defines what is valid and what isn’t).
Tip: If possible, only sync confirmed email addresses to your CRM. This will save you a lot of pain in the long run.
API limitations
Lastly, API limitations are something that needs to be addressed as early as possible.
Assuming there is an API (which is basically a must-have for any integration), it is beneficial to look at the limitations of the API. Most startups can cope with the basic API limits of most CRM systems. As an example, HubSpot offers 250,000 API calls per 24-hour period even in their free tier. On the other hand, it also limits calls to 10 per second (100 if you use OAuth). Market leader Salesforce only allows 100,000 every 24 hours but offers to purchase more.
Most of the time, you will easily fall within those limitations, but there is one thing to consider: What about your initial run? In the beginning, you will be pushing a lot of contacts and deals to your CRM (and possibly multiple times if there are problems). As a result, you might hit the daily API limit.
To mitigate this, you could test with a small data set and slowly increase the number throughout the implementation to remain within the API’s limit. For the initial migration, plan it out over multiple days or on a weekend. Alternatively, reach out to the provider and let them know your intentions. When you are in the evaluation phase (and haven’t paid for the system yet), they might be willing to increase your API allowance a little.
CRM implementation
Let’s say you are all in agreement. You picked a great CRM tool, and the engineers are confident that it can be integrated rather easily. You decided on scoping it to only push customer data and accepted robot orders. Therefore, two-way sync is not necessary, and address changes are only going to be handled in your own order system.
There are still a couple of best practices to follow during the implementation phase.
Try everything out on a test environment
In most cases, the CRM system will only be used after your integration is completed and ready to use. For this use case, it may seem appealing to just use the production system during development. After all, there is no production data you could be affecting. Once the development is done, you will simply remove all the test data you created, run an initial migration, and point your order system to this environment.
There are a couple of issues with this approach:
- You are just kicking the can down the road. Even if your go-live goes smoothly, sooner or later, there will be a feature request to change part of your integration. Given that the feature request is big enough, you will probably need another testing phase. At this point, a separate testing system is unavoidable; otherwise, you might end up messing up production data. So why wait with the setup until you are asked to implement the first feature?
- You end up with a messy configuration. It’s very likely that your CRM system needs some kind of configuration to suit the needs of your order system. Status names might need to be adjusted, custom fields usually need to be created, and so on. As most developers will need to get used to the CRM system, a configuration will be added that is not needed in the long term. In reality, this unused configuration is not removed later and might even stay in your CRM forever. By forcing the additional step of replicating the configuration from the test system to the production, you will most likely end up with a slimmer configuration on your production system.It should be noted that this can also play to your disadvantage if you forget to copy over configuration from your test to your production system, and you will end up with production errors.While there are some CRM systems that will help you compare and copy configuration items, in general, it will be useful to write down your configurations to not forget crucial items. Most CRMs provide an API to their configuration so it is possible to automate this step.
- You run a higher risk of polluting production data. Imagine for a second two developers working on an integration. You already have a staging system of the robot order system. This staging is connected to your CRM as well. Once your integration is shipped, you will need to remember to disconnect all three systems, or else, you might end up creating test data on your (now) production CRM.
All of these issues can be avoided by developing against a test system from the beginning. The production is only introduced at the very end, right before everything goes live. This way, you end up with a clean configuration, don’t run the risk of forgetting to disconnect local systems, and have a heads-up when implementing new features.
Define ID for matching up entities
Now, let’s start writing the actual integration code. Let’s take the example of syncing contacts to a CRM system. Presumably, you will need to create new contacts and update existing contacts. In order to distinguish a create from an update, you need to link the two entities. That way, you can check if the contact in your system exists on the external system.
While it seems appealing to just use the email address (after all, it’s a common identifier for a contact record), there is a more general solution—for every record, you sync to an external system hold and ID in your own database.
So, amend your contact table with a column called crm_id or external_id. This approach has a couple of advantages:
- Because it is an ID, it will not change (unlike an email address or a phone number).
- You can see if you need to create or update the entity without doing an API call first (if the external id field is empty, you can assume the contact doesn’t exist).
Before:
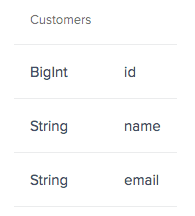
After:
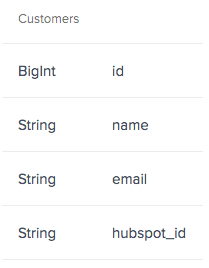
For example, let’s say you are a Ruby on Rails developer working on an application that needs to sync existing and new customers to HubSpot.
A simplified code example could look like this:
class HubspotSync def sync(customer) hubspot_return = if customer.hubspot_id.present? update(customer, customer.hubspot_id) else create(customer) end customer.update(hubspot_id: hubspot_return['companyId']) end private def create(customer) response = HTTParpty.post("https://api.hubapi.com/companies/v2/companies", map(company)) handle_response(response) end def update(customer, hubspot_id) response = HTTParpty.put("https://api.hubapi.com/companies/v2/companies/#{hubspot_id}", map(company)) handle_response(response) end def handle_response(response) raise RuntimeError, "Unexpected Status code: #{response.code}" if response.code >= 500 JSON.parse(response.body) end def map(company) # mapping code goes here { properties: [ name: 'name', value: company.name ] } end end Notice how we are taking advantage of saving the companyId that is returned from HubSpot. Not only does it help us to determine if we want to update or create a company on HubSpot, but we can also see in the database table which entities are already synced to HubSpot and which are still missing.
When it comes to mapping fields, go freestyle
I have seen projects where implementation is preceded by creating a giant Excel spreadsheet defining which columns go where in the CRM system, with annotations of how data should be transformed.
In reality, there are just a few ways to represent contacts and deals. So instead of spending a lot of time thinking about how exactly you want to map, why not start with an experiment? Give the developer some space to figure out the mapping but also keep in touch so that questions can arise early.
At least for the general contact fields (name, email address, phone number, address), the mapping will be very simple, and transformations are usually trivial.
When it comes to status mapping for deals, a little bit more communication is helpful (sometimes, the first status is called open, sometimes new, and sometimes, the status model doesn’t match 100% so you’ll have to group statuses together). Instead of coming up with the perfect solution, look at your current data and see how it would best fit into the data model of the CRM. After all, you are an agile company, right?
In the example above, you can see a map method that converts our Rails model into a regular hash that is understood by HubSpot. For this particular use case, the only synced item is the name. For more advanced usage, you probably want to include more fields, but for a great outcome, start with an educated guess and communicate with the business side often for the details.
Consider retries
Let’s get down to the more technical level: implementing the actual sync between your system and the CRM. It’s almost a given that the integration will take place over an HTTP connection. Most systems provide an HTTP API, and all programming languages will let you make HTTP calls very easily.
Unfortunately, no matter how much money you spend on a CRM system, eventually, it won’t be reachable. This will happen at some point and there is nothing you can do about it. So, you might as well factor this in when you are developing your integration.
What this means in practice is—whenever you call an API, make sure your call is retried in case of a problem (500 status code from the other side). Implementing retries is something that is usually provided by third-party libraries of your language of choice.

In addition to just retrying, you might want to consider logging what exactly happened. Getting a notification about an error that is already solved in the first retry can be frustrating.
So, instead of spamming your error channel with resolved issues, record all callouts with the number of retries to get a feel of how reliable the system is – a system that you just paid a lot of money for.
If we take the class that we created as an example and we stay in the context of Ruby on Rails, we can simply wrap the call in an ActiveJob and be fairly certain the call will succeed eventually. The handle_response method will raise an error in case of an unexpected status code, and ActiveJob will attempt a retry with an exponential backoff. For a more advanced solution, you should also consider 4xx status codes so that a retry is prevented and an error message is raised instead.
class HubspotSyncJob < ApplicationJob def perform(customer) HubspotSync.new.sync(customer) end End Make sure the system is actually used
OK, let’s assume you shipped it all. You are super proud of your work, and the system goes live. Now what? This is just the beginning. Because no matter how much testing you are doing, there will always be bugs and requested changes.
Problem is, you are not going to find out about these unless you actually use your system. And this happens for all kinds of reasons—the sales department is currently too busy to start using it, strategy changed, or even new systems are already being evaluated.
So, in order to avoid potential issues in the long term, make sure you have eliminated all obstacles that prevented production usage of the system. Communicate often between teams to get new requirements aligned. And if you find out that the system is just not going to work for you, turn off the integration. It sounds harsh and can feel very frustrating, but it’s less frustrating than always having to fix data inconsistency issues and deal with workarounds.
In the end, an integration project is a hell of a project, and there are a lot of things that can go wrong. It’s not very popular among engineers for a number of reasons, but it can be rewarding to see that an implementation has a positive impact on the productivity of people sitting next to you.
So for engineers—try to understand the needs of an external system such as a CRM or an invoicing system by asking concrete questions such as: How will this product make your life easier? Have you considered competitors? Why don’t they work?
For everyone else involved—get the engineers in as early as possible, trust them when they point out red lines, and don’t opt for a cheap plan when you can see that the implementation of the integration will make it a lot harder in the long run.
The Toptal Engineering Blog is a hub for in-depth development tutorials and new technology announcements created by professional software engineers in the Toptal network. You can read the original piece written by Leif Gensert here. Follow the Toptal Design Blog on Twitter and LinkedIn.
Published May 21, 2020 — 18:00 UTC