The human mind has different mechanisms for processing individual pieces of information and sequences. For instance, we have a definition of the word “like.” But we also know that how “like” is used in a sentence depends on the words that come before and after it. Consider how you would fill in the blanks in the following two sentences:
Would you like … coffee?
Would you like … a walk?
We see sequences everywhere. Videos are sequences of images, audio files are sequences of sound samples, music is sequences of notes. In all cases, there is a temporal dependency between the individual members of the sequence. Changing the order of frames in a video will render it meaningless. Changing the order of words in a sentence or article can completely change its meaning.
As with the human brain, artificial intelligence algorithms have different mechanisms for the processing of individual and sequential data. The first generation of artificial neural networks, the AI algorithms that have gained popularity in the past years, were created to deal with individual pieces of data such as single images or fixed-length records of information. But they were not suitable for variable-length, sequential data.
[Read: The key differences between rule-based AI and machine learning]
Recurrent neural networks (RNN), first proposed in the 1980s, made adjustments to the original structure of neural networks to enable them to process streams of data.
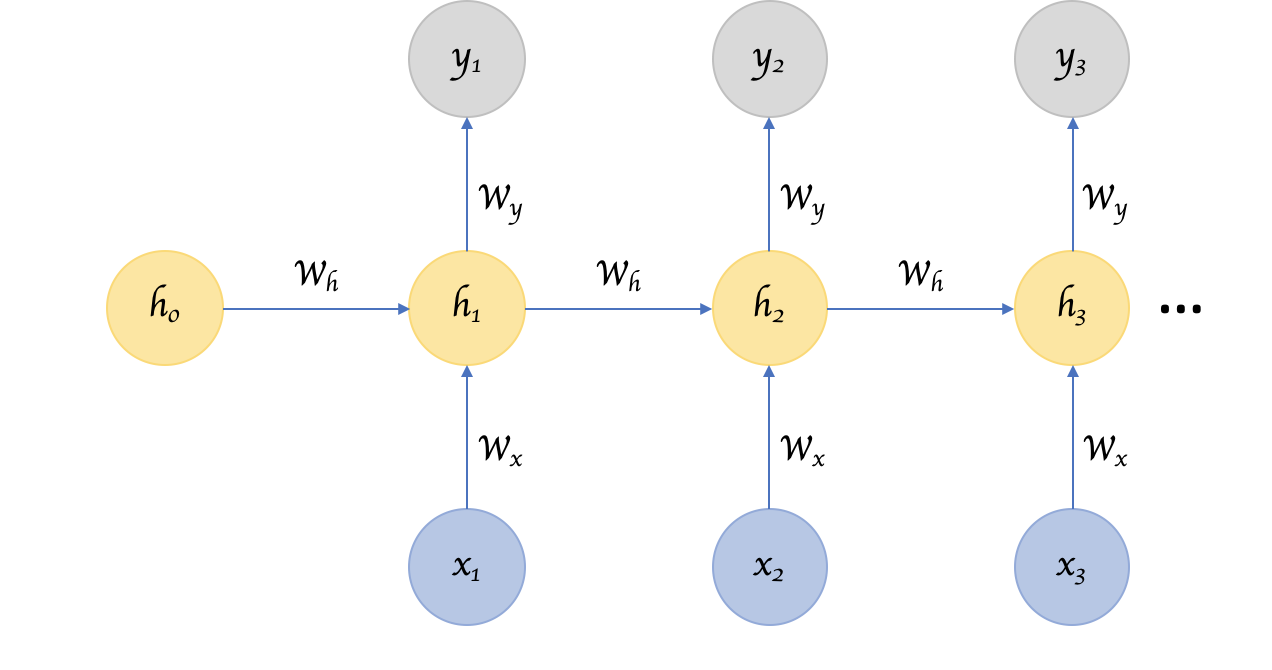
Feedforward vs recurrent neural networks
Multi-layer perceptrons (MLP) and convolutional neural networks (CNN), two popular types of ANNs, are known as feedforward networks. In feedforward networks, information moves in one direction. They receive input on one end, process the data in their hidden layers, and produce an output value. For instance, an image goes through one end, and the possible class of the image’s contents come out the other end.

After processing a piece of information, a feedforward network forgets about it and processes the next input independently. Therefore, feedforward networks know nothing about sequences and temporal dependency between inputs.
Recurrent neural networks, on the other hand, use the result obtained through the hidden layers to process future input.

The feedback of information into the inner-layers enables RNNs to keep track of the information it has processed in the past and use it to influence the decisions it makes in the future. This is why when a recurrent neural network is processing a word as an input, what came before that word will make a difference.
Different modes of recurrent neural networks
Depending on the type of use case, RNNs can be adjusted to one of the following modes:
The one-to-many mode is used when a single input is mapped onto multiple outputs. For instance, an image-captioning system takes a single image and outputs a description.

The many-to-one mode is used when an input sequence is mapped onto a single output. For instance, a sentiment analysis RNN takes a sequence of words (e.g., a tweet) and outputs the sentiment (e.g., positive or negative).

The many-to-many mode, also known and sequence-to-sequence model, is used when an input sequence is mapped onto an output sequence. For instance, a machine translation RNN can take an English sentence as input and produce the French equivalent.

Applications of recurrent neural networks
Some of the most important applications of RNNs involve natural language processing (NLP), the branch of computer science that helps software make sense of written and spoken language.
Email applications can use recurrent neural networks for features such as automatic sentence completion, smart compose, and subject suggestions. You can also use RNNs to detect and filter out spam messages.
Chatbots are another prime application for recurrent neural networks. As conversational interfaces, they must be able to process long and variating sequences of text, and respond with their own generated text output. This is an example of the many-to-many RNN mode.
Other users of RNNs in NLP include question answering, document classification, machine translation, text summarization, and much more.
Another use for recurrent neural networks that is related to natural language is speech recognition and transcription. RNNs can be trained to convert speech audio to text or vice versa.
But the use of recurrent neural networks is not limited to text and language processing. RNNs can be applied to any type of sequential data.
For instance, if you train a recurrent neural network on Irish folklore music, it can generate its own sequences of notes in Celtic style.
RNNs are also useful in time series prediction. For instance, a recurrent neural network trained on weather data or stock prices can generate forecasts for the future.
Beyond recurrent neural networks
The original RNNs suffered from a problem known as “vanishing gradients.” Without going into the technical details, the vanishing gradient problem means that old data loses its effect as the RNN goes into more cycles. For instance, if you’re processing text, the words that come at the beginning start to lose their relevance as the sequence grows longer. The vanishing gradient problem is not limited to recurrent neural networks, but it becomes more problematic in RNNs because they are meant to process long sequences of data.
To solve this problem, German scientist Jürgen Schmidhuber and his students created long short-term memory (LSTM) networks in mid-1990s. LSTM is a special type of RNN that has a much more complex structure and solves the vanishing gradient problem. It has replaced RNNs in most major areas such as machine translation, speech recognition, and time-series prediction.

More recently, Transformers, another type of sequence-processing neural network introduced in 2017, has gained popularity. Transformers leverage a technique called “attention mechanism,” found in some type of RNN structures, to provide better performance on very large data sets.
Transformers have become the key component of many remarkable achievements in AI, including huge language models that can produce very long sequences of coherent text. Many large tech companies have adopted their own version of Transformers and have made them available to the public. Last year, the Allen Institute for AI (AI2), used transformers to create an AI that can answer science questions.

The limits of recurrent neural networks
One thing to note is that RNNs (like all other types of neural networks) do not process information like the human brain. They are statistical inference engines, which means they capture recurring patterns in sequential data. They have no understanding of the concepts that those data points present. This is why you need tons of data to obtain acceptable performance from RNNs.
For instance, OpenAI’s GPT-2 is a 1.5-billion-parameter Transformer trained on a very large corpus of text (millions of documents). It can produce interesting text excerpts when you provide it with a cue. But it can also make very dumb mistakes, such as not being able to make sense of numbers and locations in text. In a critical appraisal of GPT-2, scientist Gary Marcus expands on why neural networks are bad at dealing with language.
In contrast, for us humans, finding patterns in sequences is just one of the many tricks we have at our disposal. We have plenty of other mechanisms to make sense of text and other sequential data, which enable us to fill in the blanks with logic and common sense.
The achievement and shortcoming of RNNs are a reminder of how far we have come toward creating artificial intelligence, and how much farther we have to go.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech and what we need to look out for. You can read the original article here.
Read next: A look inside the $1B internet fund that’s beating the market by more than 200%
Celebrate Pride 2020 with us this month!
Why is queer representation so important? What’s it like being trans in tech? How do I participate virtually? You can find all our Pride 2020 coverage here.