“You don’t want to know how the sausage gets made.”
As much as you’ve probably heard this refrain, I’m here to say that, really, you do, or at least you should. If you’re going to be shoving a bratwurst in your mouth hole, don’t you want to know if somebody was pouring sawdust into your sausage? The same goes for tech. Now with AI large language models taking the tech world by storm, you’re damn tooting we want to know what kind of data is being used to make ChatGPT or any other LLM.
- Off
- English
On Tuesday, OpenAI released its GPT-4 model, citing it as the most advanced AI language model it’s ever created with “greater accuracy” and “broader knowledge.” Though you’ll just have to take the company’s word for it. Despite its name, OpenAI isn’t letting just anybody peak under the hood of its new Ferrari-class language model. In the paper released with GPT-4, the company wrote:
“Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar.”
Advertisement
OpenAI president Greg Brockman confirmed with TechCrunch that GPT-4 is now trained on images as well as text, but he was still unwilling to discuss specifics about where those images came from, or anything else about its training data. OpenAI is fighting back a proposed class action lawsuit targeting its partnership with GitHub for its AI assistant Copilot tool. There’s other ongoing lawsuits regarding images used to train AI image generators, so OpenAI may be trying to protect itself from any legal surprises.
Gizmodo reached out to OpenAI to learn more about its decision making, but we never heard back. In a Wednesday interview with The Verge, OpenAI co-founder Ilya Sutskever let loose on just how “wrong” the company was for releasing its training data in previous years. He said making AI open source was “a bad idea” not just because of competition, but because artificial general intelligence, or AGI will be so “potent.” Mind you, there is no such thing as AGI, as in technology equivalent to a real, aware artificial intelligence. It’s all just speculative, but OpenAI seems to think it’s already on the ground floor.
G/O Media may get a commission
Advertisement
The company said it shares some data with outside auditors, but it’s not likely we’ll ever see those researchers’ full GPT-4 dissection. OpenAI was once a nonprofit before creating a for-profit subsidiary in the grand hopes of becoming the biggest force of AI on the planet (even original OpenAI investor Elon Musk seems confused how this happened). So now, the Sam Altman-headed AI wonks at OpenAI said they need to “weigh the competitive and safety consideration… against the scientific value of further transparency.”
There’s few ways to tell what specific kinds of bias GPT-4 has
Ben Schmidt, a former history professor now working as VP of Information Design at AI data set analysis company Nomic, said that the lack of information on GPT-4’s data set is extremely concerning because that data could provide clues for what kind of biases an AI model might have. Without it, outside groups can only guess.
Advertisement
The company has been going down this road for a while. The company’s previous language model GPT-3 was trained on many, many terabytes of text uploaded to the internet. The company has acknowledged this leads to some groups not on the internet being unrepresented and informs the AI of certain biases.
Advertisement
OpenAI admitted in its paper GPT-4 has “various biases in its outputs that we have taken efforts to correct but which will take some time to fully characterize and manage.” The goal is to make the system reflect a “wide swath of users’ values” even the ability to customize those “values.” The company’s own red teaming initiatives showed that GPT-4 can rival human propagandists, especially coupled with a human editor. Even with that admission, researchers outside OpenAI would not know where it may be getting any of that bias from.
After OpenAI released GPT-4, AI security researchers at Adversera conducted some simple prompt injection attacks to find out how it can manipulate the AI. These prompts trick the AI into overriding its own safeguards. The AI could then create an edited article to, for example, explain how to best destroy the world. In a much more pertinent example for our demented political environment, Adversera researchers could also get the AI to write an edited article using subversive text and dog whistles to attack LGBTQ+ people.
Advertisement
Without knowing where GPT-4 derives its information from, it’s harder to understand where the worst harms lie. University of Washington computational linguistics professor Emily Bender wrote on Twitter this has been a constant problem with OpenAI going back to 2017. She said OpenAI is “willfully ignoring the most basic risk mitigation strategies, all while proclaiming themselves to be working towards the benefit of humanity.”
Advertisement
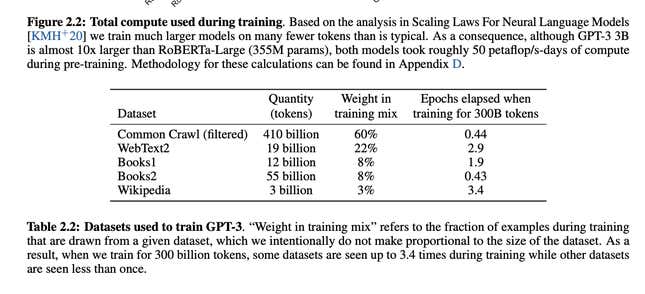
Even if GPT-3 was more open about its training data, it still remains vague on specifics. In an email to Gizmodo, Schmidt pointed to the GPT-3 paper which included data points of “Books1” and “Books2.” Those two make up 16% of the data set, yet researchers can only speculate what those mean, and which books could have been included in the data set (especially since its not like the web scrapers ask authors’ permission before gobbling up all that data). It was even worse in previous years. Schmidt said OpenAI launched GPT-2 using scraped data that tried to parse “high-quality” pages based on how many Reddit upvotes it received.
Advertisement
It’s up to OpenAI’s relatively opaque filters whether highly upvoted r/the_donald made it into various versions of OpenAI’s training set. The company said it worked with researchers and industry professionals, and it expects to do even more tests in the future. Still, the system will “continue to reinforce social biases and worldviews.”
OpenAI is getting too close to becoming just like every other big tech company
In its latest paper, OpenAI wrote “We will soon publish recommendations on steps society can take to prepare for AI’s effects and initial ideas for projecting AI’s possible economic impacts,” though there’s no hint of a deadline for that assessment. The company cites its own internal data for how the newest language model produces answers to “sensitive prompts,” namely medical advice or self-harm, around 23% of the time. It will respond to “disallowed prompts” .73% of the time.
Advertisement
That last set of data is based on the Real Toxicity Prompts dataset, an open source evaluating tool that includes 100,000 sentence snippets containing some pretty nasty content. In that way, we have a small idea of what GPT-4 doesn’t like, but nobody outside the company understands much of what kind of content it may be regurgitating. After all, researchers have shown AI systems are fully capable of simply regurgitating sentences from its data set.
Considering how GPT-4 is capable of lying to humans in order to solve a task like solving a CAPTCHA, it would be good to know where it might be getting some of its ideas from. Only thing is, OpenAI isn’t telling. Considering the company has a multi-billion dollar partnership with Microsoft on the line, and now that its API has opened the door to practically every tech company under the sun paying for AI capabilities, there’s a question whether the pursuit of the almighty dollar has overrode the case for transparency and academic rigor.
Advertisement
Schmidt noted that recent papers from Google on its Gopher AI and Meta’s LlaMA model were both more transparent about its training data, including the size, origin, and processing steps, though of course neither company released the full data set for users to peruse. We reached out to Anthropic, a Google-backed startup made of some ex-OpenAI staff, to see if it had any paper on its newly-announced Claude AI, but we did not immediately hear back.
“It would be a shame if they followed OpenAI in keeping as much secret as possible,” Schimdt said.
Advertisement
No, OpenAI isn’t nearly as opaque as other tech companies out there. The GPT-4 paper offers a great deal of information about the system, but it’s only cursory, and we have to trust the company in sharing data accurately. Where OpenAI leads, other AI-based companies will follow, and the company can’t simply straddle the line between being fully transparent and becoming a Gollum-esque hoarder of its “precious” training data. If it keeps on this path, it won’t be long before OpenAI is just another Meta or Amazon, sapping up enormous amounts of data to sell to the highest bidder.
Services Marketplace – Listings, Bookings & Reviews