Machine learning, the subset of artificial intelligence that teaches computers to perform tasks through examples and experience, is a hot area of research and development. Many of the applications we use daily use machine learning algorithms, including AI assistants, web search and machine translation.
Your social media news feed is powered by a machine learning algorithm. The recommended videos you see on YouTube and Netflix are the result of a machine learning model. And Spotify’s Discover Weekly draws on the power of machine learning algorithms to create a list of songs that conform to your preferences.
But machine learning comes in many different flavors. In this post, we will explore supervised and unsupervised learning, the two main categories of machine learning algorithms. Each subset is composed of many different algorithms that are suitable for various tasks.
A very quick note on machine learning
Before we dive into supervised and unsupervised learning, let’s have a zoomed-out overview of what machine learning is.
In their simplest form, today’s AI systems transform inputs into outputs. For instance, an image classifier takes images or video frames as input and outputs the kind of objects contained in the image. A fraud detection algorithm takes payment data as input and outputs the probability that the transaction is fraudulent. A chess-playing AI takes the current state of the chessboard as input and outputs the next move.
Classic approaches to developing intelligence systems, known as symbolic artificial intelligence, required programmers to explicitly specify the rules that mapped inputs to outputs. While there are many benefits to symbolic AI, it has limited use in fields where the input can come in many diverse forms such as computer vision, speech recognition, and natural language processing.
In contrast, machine learning uses a different approach to developing behavior. When creating an ML system, developer create a general structure and train it on many examples. These examples can be pictures with their corresponding images, chess game data, items purchased by customers, songs listened to by users, or any other data that is relevant to the problem the AI model wants to solve. After analyzing the training data, the machine learning algorithm tunes its internal parameters to be able to deal with new input data.
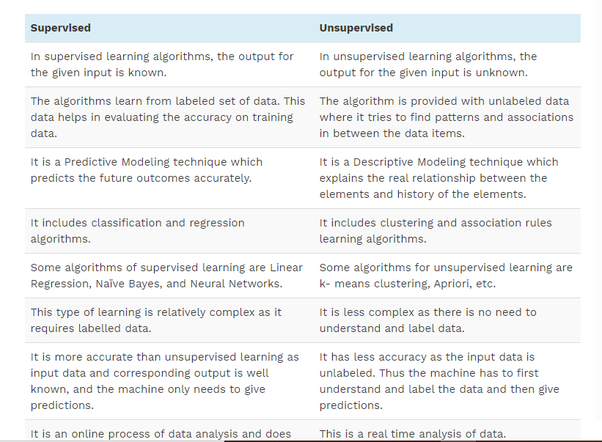
Supervised learning

If you follow artificial intelligence news, you’ve probably heard that AI algorithms need a lot of human-labeled examples. Those stories refer to supervised learning, the more popular category of machine learning algorithms.
Supervised machine learning applies to situations where you know the outcome of your input data. Say you want to create an image classification machine learning algorithm that can detect images of cats, dogs, and horses.
To train the AI model, you must gather a large dataset of cat, dog, and horse photos. But before feeding them to the machine learning algorithm, you must annotate them with the name of their respective classes. Annotation might include putting the images of each class in a separate folder, using a file-naming convention, or appending meta-data to the image file. This is the laborious manual task that is often referred to in stories that mention AI sweatshops.
Once the data is labeled, the machine learning algorithm (e.g. a convolutional neural network or a support vector machine) processes the examples and develops a mathematical model that can map each image to its correct class. If the AI model is trained on enough labeled examples, it will be able to accurately detect the class of new images that contain cats, dogs, horses.
Supervised machine learning solves two types of problems: classification and regression. The example explained above is a classification problem, in which the machine learning model must place inputs into specific buckets or categories. Another example of a classification problem is speech recognition.
Regression machine learning models are not limited to specific categories. They can have continuous, infinite values, such as how much a customer will pay for a product or the likelihood that it will rain tomorrow.
Some common supervised learning algorithms include the following:
Unsupervised learning

Suppose you’re an e-commerce retail business owner who has thousands of customer sales records. You want to find out which customers have shared buying habits so that you can use the information to make relevant recommendations to them and improve your upsell policy. The problem is that you don’t have predefined categories to divide your customers into. Therefore, you can’t train a supervised machine learning model to classify your customers.
This is a clustering problem, the main use of unsupervised machine learning. Unlike supervised learning, unsupervised machine learning doesn’t require labeled data. It peruses through the training examples and divides them into clusters based on their shared characteristics.
A well-trained unsupervised machine learning algorithm will divide your customers into relevant clusters. This will help you predict the products that customers will buy based on their shared preferences with other people in their cluster.
K-means is a well-known unsupervised clustering machine learning algorithms. One of the challenges of using k-means is knowing how many clusters to divide your data into. Too few will pack data that are not very similar while too many clusters will only make your model complex and inaccurate.
Aside from clustering, unsupervised learning can also perform dimensionality reduction. You can use dimensionality reduction when you have a dataset with too many features. Say you have a table of information about your customers, which has 100 columns. Having so much data about your customers might sound interesting. But in reality, it’s not.
As the number of features in your data increases, you’ll also need a larger sample set to train an accurate machine learning model. You may not have enough samples to train a 100-column model. Too many features also increase the chances of overfitting, which effectively means that your AI model performs well on the training data but poorly on other data.
Unsupervised machine learning algorithms can analyze the data and find the features that are less relevant and can be dropped to simplify the model without losing valuable insights. For instance, in the case of our customer table, after running it through the dimensionality reduction algorithm, we might find out that the features related to the age and home address of the customer have very little relevance and we can remove them.
Principle component analysis (PCA) is a popular dimensionality reduction machine learning algorithm.
Some security analysts also use unsupervised machine learning for anomaly detection to identify malicious activity in an organization’s network.
One of the benefits of unsupervised learning is that it doesn’t require the laborious data labeling process that supervised learning must go through. However, the tradeoff is that evaluating the effectiveness of its performance is also very difficult. In contrast, it’s very easy to measure the accuracy of supervised learning algorithms by comparing their output to the actual labels of their test data.
This article was originally published by Ben Dickson on TechTalks, a publication that examines trends in technology, how they affect the way we live and do business, and the problems they solve. But we also discuss the evil side of technology, the darker implications of new tech and what we need to look out for. You can read the original article here.
Published June 1, 2020 — 07:46 UTC